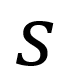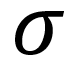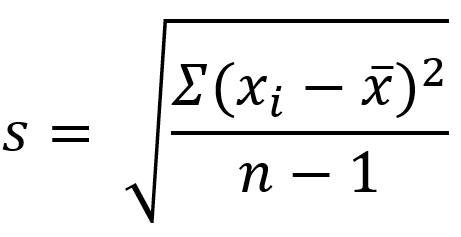Google, save me!
Variation:
- A change or difference in condition, amount, or level, typically with certain limits
- A different or distinct form or version of something
Variability:
lack of consistency or fixed pattern; liability to vary or change.
Why Does Variation Matter?
Here’s the thing — there’s no need to study/use data when everything is identical. It’s the differences in everything around us that creates this need to use, understand, and communicate data. Our minds like patterns, but a distinction between natural and meaningful variation is not intuitive – yet it is important.
Considering how often we default to summary statistics in reporting, it’s not surprising that distinguishing between significant insights and natural variation is difficult. Not only is it foreign, the game changes depending on your industry and context.
What’s So Complicated About Variation?
Let’s set the stage to digest the concept of variation by identifying why it’s not an innate concept.
At young ages, kids are taught to look for patterns, describe patterns, predict the next value in a pattern. They are also asked, “which one of these is not like the other?”
But this type of thinking generally isn’t cultivated or expanded. Let’s look at some examples:
1) Our brains struggle with relative magnitudes of numbers.
We have a group of 2 red and 2 blue blocks. Then we start adding more blue blocks. At what point do we say there are more blue blocks? Probably when there are 3 blue, 2 red, right?
Instead, what if we started with 100 blocks? Or 1000? 501 red/499 still seems the same, right? Understanding how the size of the group modifies the response is learned – as sample/population size increases, variability ultimately decreases.
Something to ponder: When is $300 much different from $400? When is it very similar?
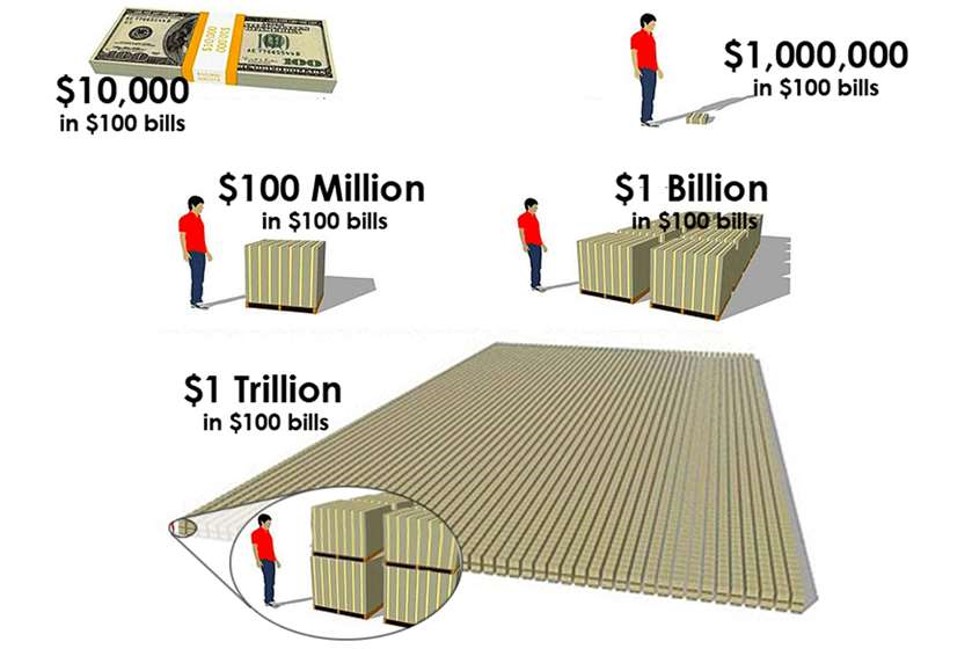
“For example, knowing that it takes only about eleven and a half days for a million seconds to tick away, whereas almost thirty-two years are required for a billion seconds to pass, gives one a better grasp of the relative magnitudes of these two common numbers.”
― Innumeracy: Mathematical Illiteracy and Its Consequences
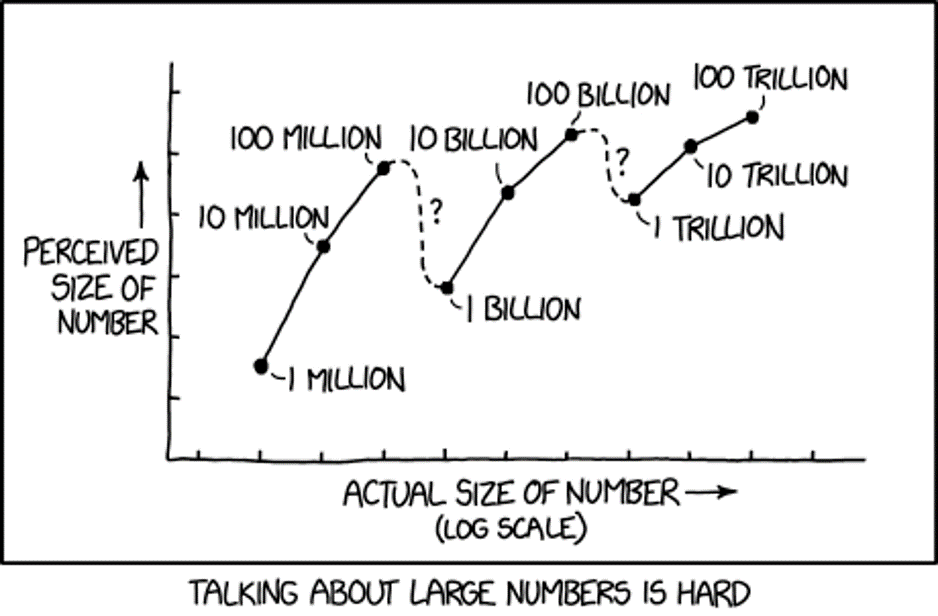
We understand that 100 times 10 is 1000. And mathematically, we understand that 1 Million times 1000 is 1 Billion. What our brains fail to recognize is the difference between 1000 and 100 is only 900, but the difference between 1 million and 1 billion is 999,000,000! We have trouble with these differences in magnitudes:
We kind of “glaze” over these concepts in U.S. math classes. But they are not intuitive!
2) We misapply the Law of Large Numbers
My favorite example misapplying the Law of Large Numbers is called The Gambler’s Fallacy, or Monte Carlo Fallacy. Here’s an easy example:
Supposed I flip a fair coin 9 times in a row and it comes up heads all 9 times, what is your prediction for the 10th coin flip? If you said tails because you think tails is more likely, you just fell for the Gambler’s Fallacy. In fact, the probability for each coin flip is exactly the same each time AND each flip is independent of another. The fact that the coin came up heads 9 times in a row is not known to the coin, or gravity for that matter. It is natural variation in play.
The Law of Large Numbers does state that as the number of coin flips increase (n>100, 1000, 10000, etc), the probability of heads gets closer and closer to 50%. However, the Law of Large numbers does NOT play out this way in the short run — and casinos cash in on this fallacy.
Oh, and if you thought the 10th coin flip would come up heads again because it had just come up heads 9 times before, you are charged with a similar fallacy, called the Hot Hand Fallacy.
3) We rely too heavily on summary statistics

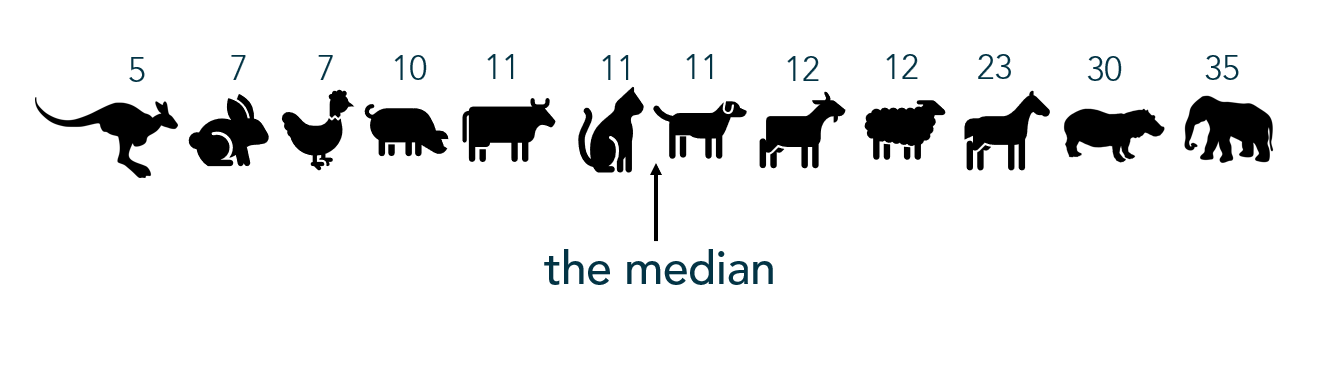
Once people start learning “summary statistics”, variation is usually only brought in as a discussion as a function of range. Sadly, range only considers minimum and maximum values and ignores any other variation within the data. Learning beyond “range” as a measure of variation/spread also helps hone in on differences between mean and median and when to use each.
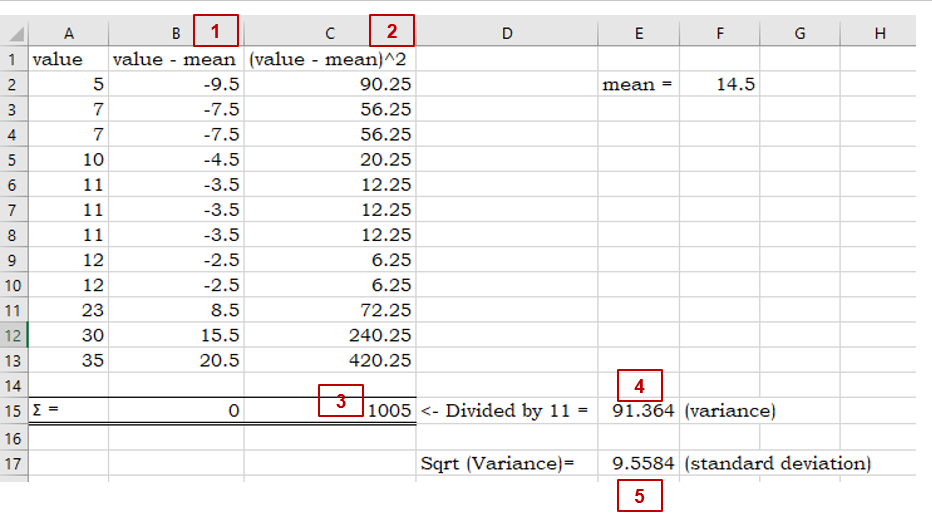
Standard deviation and variance also measure variation; however, the calculation relies on the mean (average) and when there is a lack of normality to the data (e.g. the data is strongly skewed), standard deviation and variance can be an inaccurate measure of the spread of the data.
In relying on summary statistics, we find ourselves looking for that one number – that ONE source of truth to describe the variation in the data. Yet, there is no ONE number that clearly describes variability – which is why you’ll see people using the 5-number summary and interquartile range. But the lack of clarity in all summary statistics makes the argument for visualizing the data.
When working with any kind of data, I always recommend visualizing the variable(s) of interest first. A simple histogram, dot plot, or box-and-whisker plot can be useful in visualizing and understanding the variation present in the data.
Start Simple: Visualize Variation
Before calculating and visualizing uncertainty with probabilities, start with visualizing variation by looking at the data one variable at a time at a granular or dis-aggregated level.
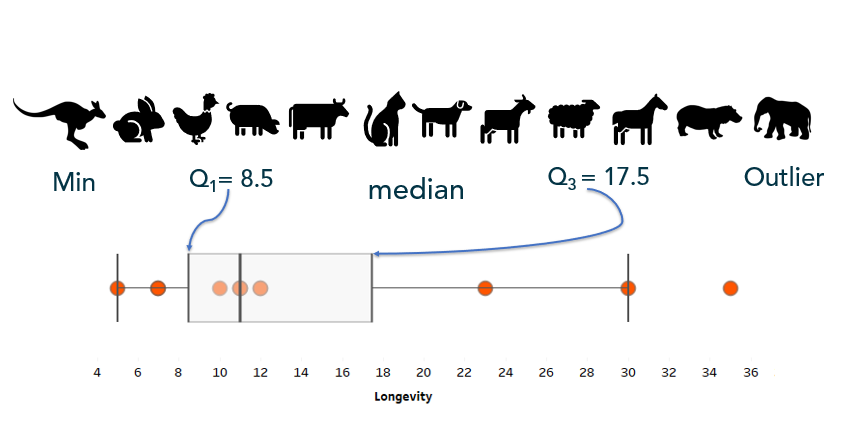
Box-and-whisker can, not only give show you outliers, these charts can also give a comparison of consistency within a variable:
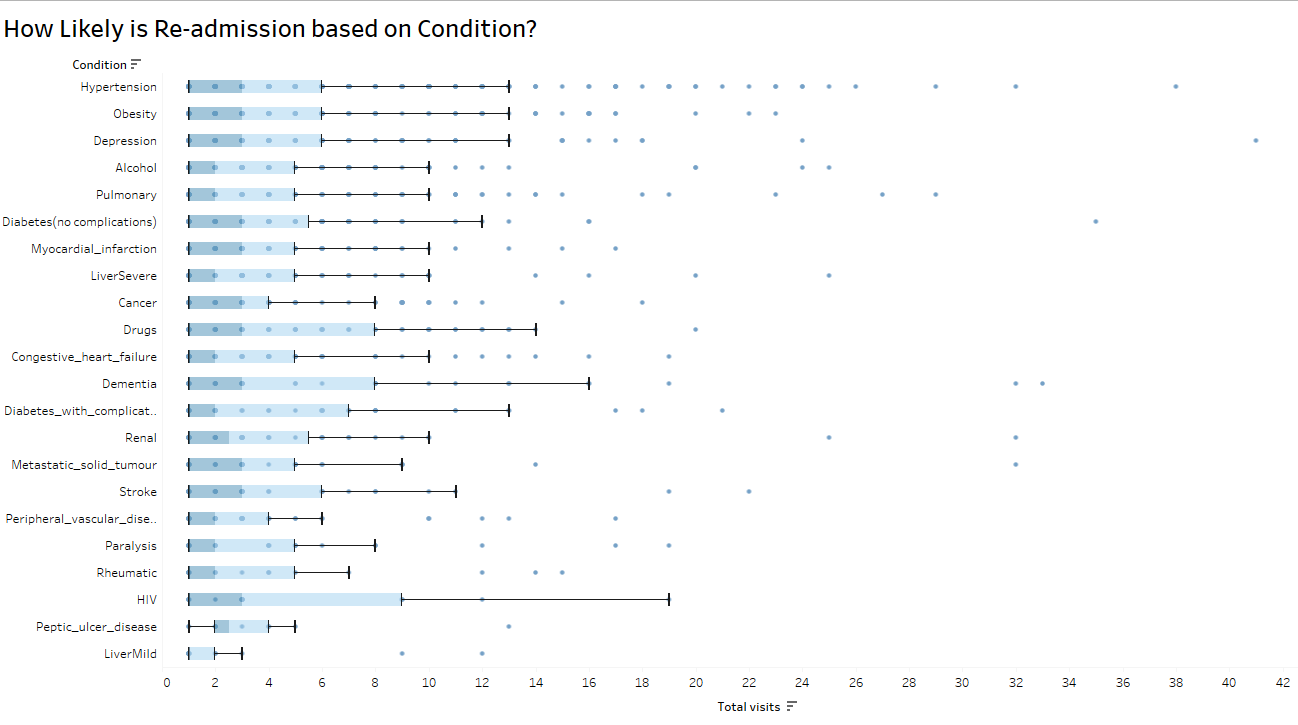
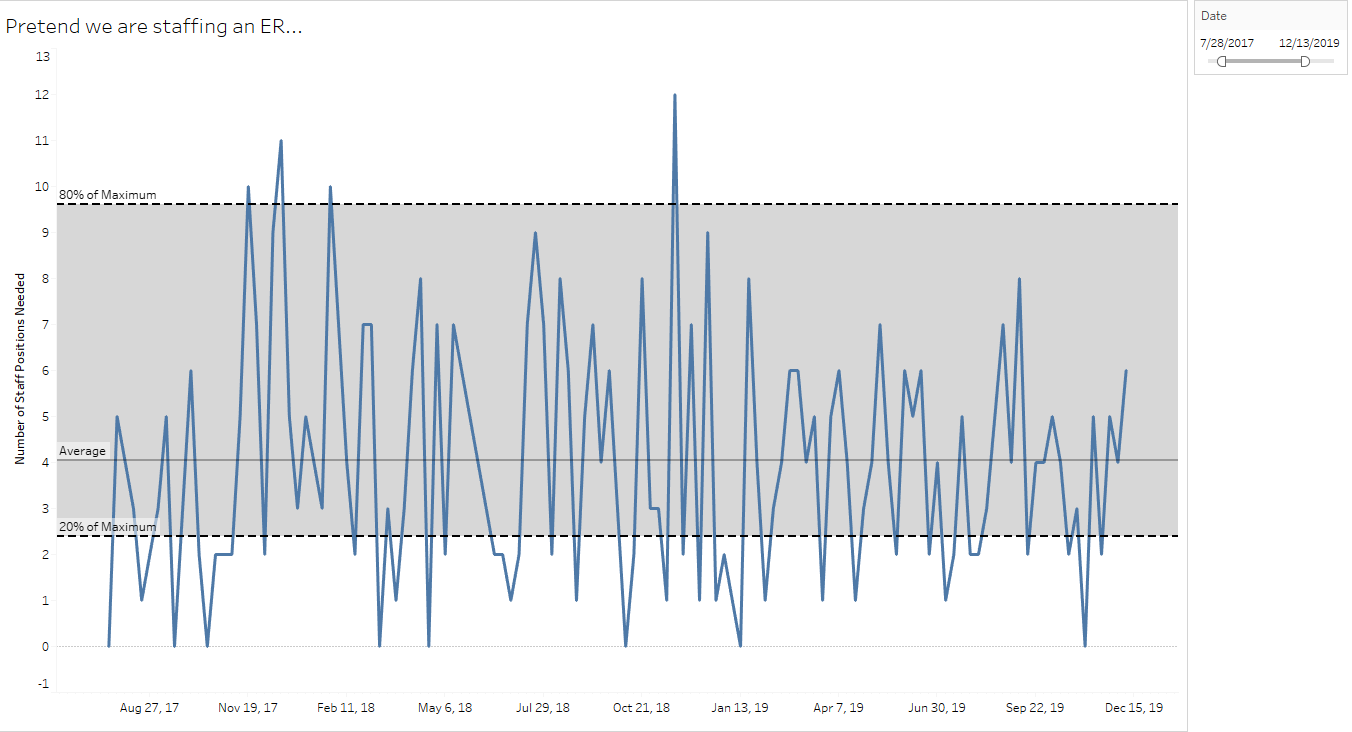
Simple control charts can capture natural variation for high-variability organizational decision-making, such as staffing an emergency room:
Think of histograms as a bar graph for continuous metrics. Histograms show the distribution of the variable (here, diameters of tortillas) over a set of bins of the same width. The width of the bar is determined by the “bin size” – smaller sets of ranges of tortilla diameters – and the height of the bar measures the frequency, or how many tortillas measured within that range. For example, the tallest bar indicates there are 26 tortillas measuring between (approximately) 6.08 and 6.10 cm.
I can’t stress enough the importance of changing the bin size to explore the variation further.
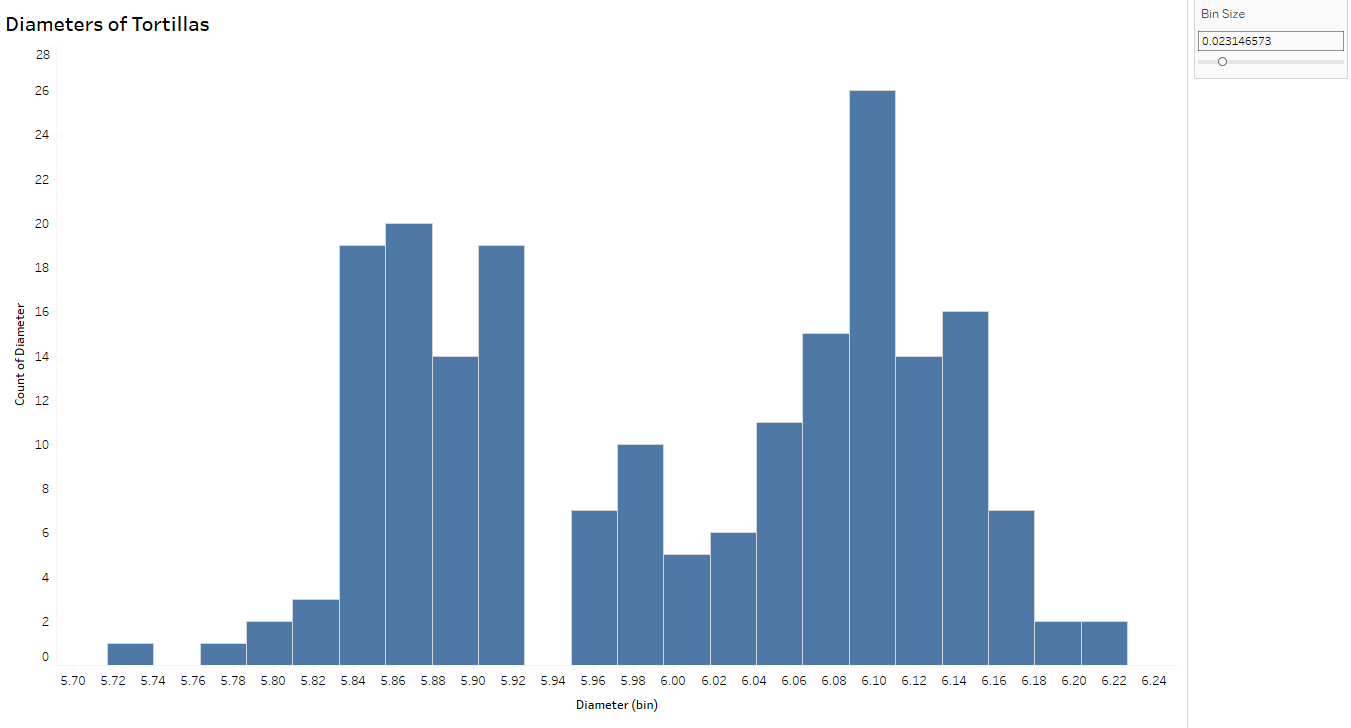
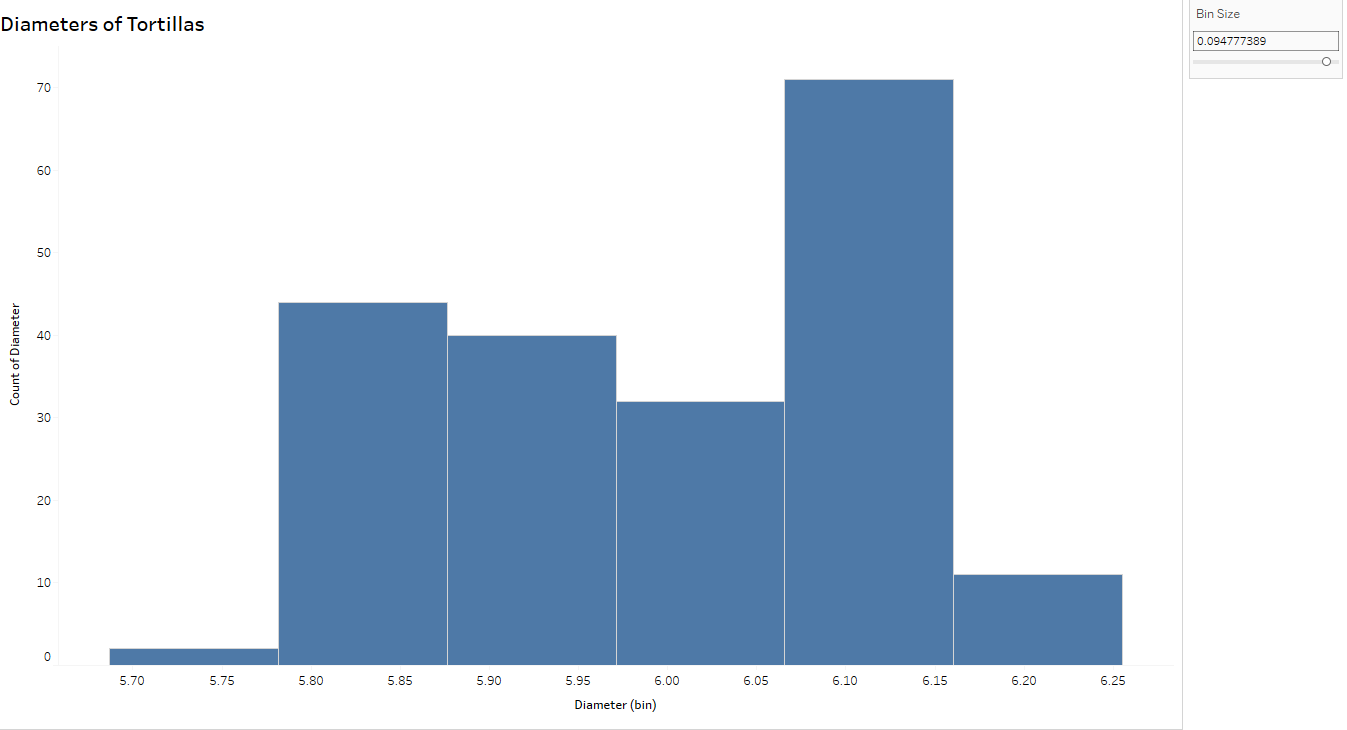
Notice the histogram with the wider bin size (below) can hide some of the variation you see above. In fact, the tortillas sampled for this process came from two separate production lines- which you can conclude from the top histogram but not below, thus emphasizing the importance of looking at variability from a more granular level.
Resources
Recently, Storytelling with Data blogged about visualizing variability. I’m also a fan of Nathan Yau’s Flowing Data post about visualizing uncertainty.
Brittany Fong has a great post about disaggregated data, as well as Steve Wexler’s post on Jitter Plots.
I plan a follow-up post diving more into probabilities and uncertainty. For now, I’m going to leave you with this cartoon from XKCD, called “Certainty.“