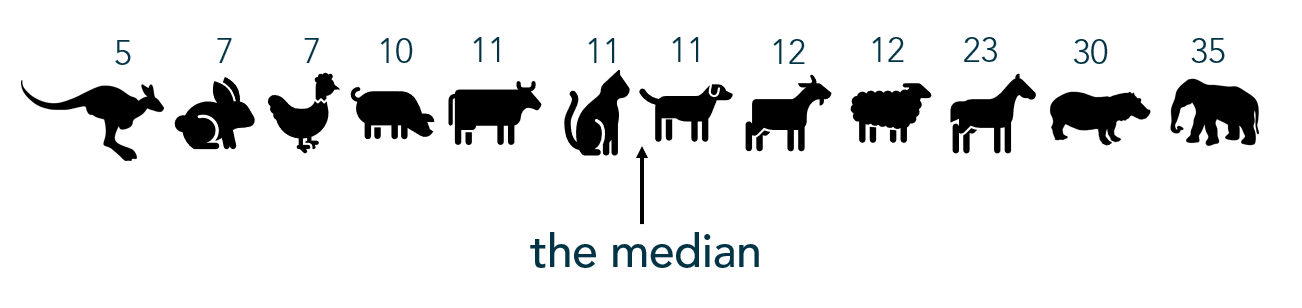
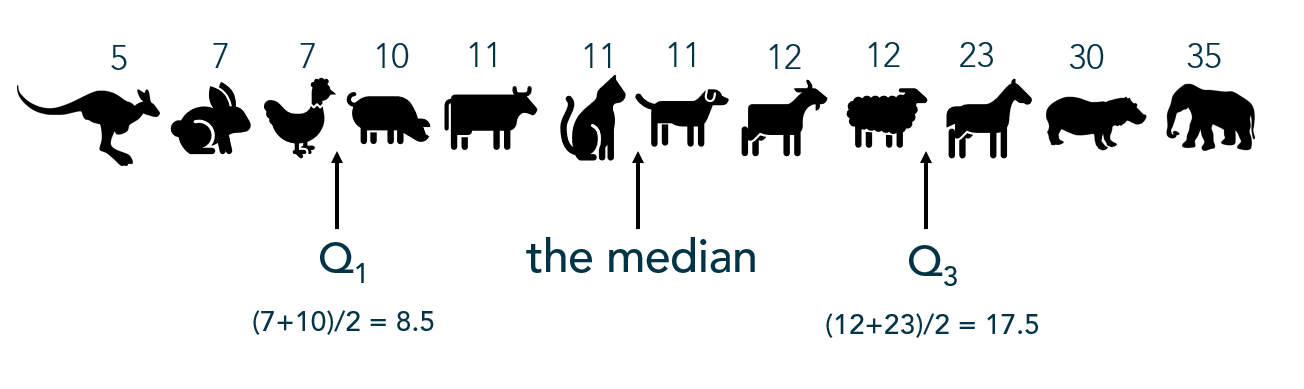
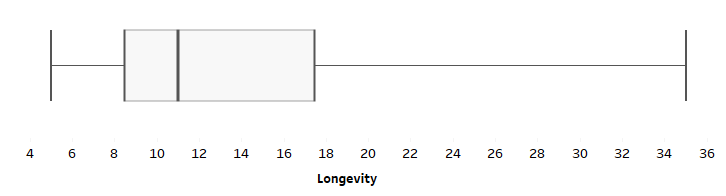
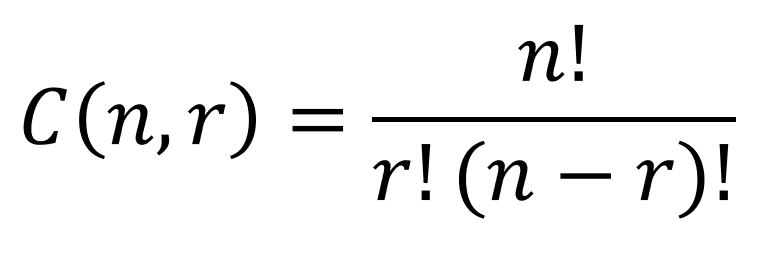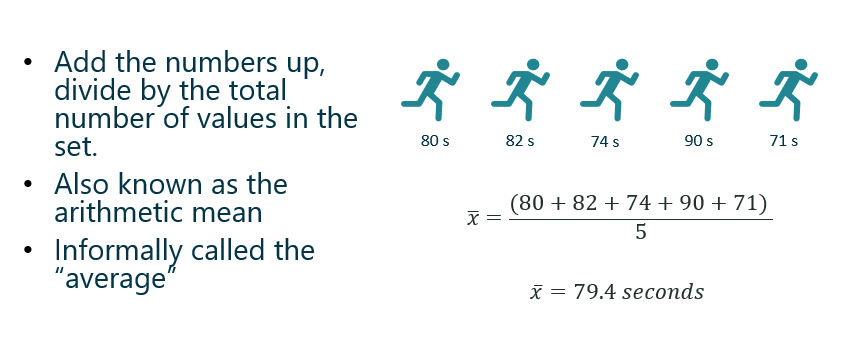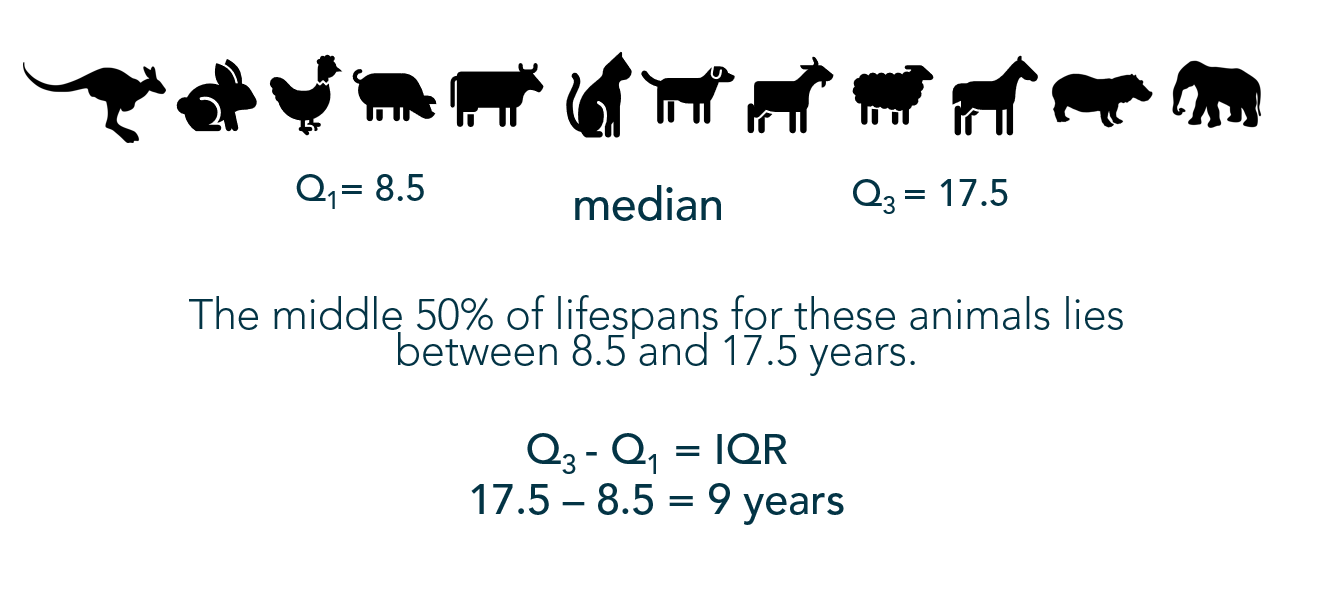To be fair, there are probably thousands of people more qualified to write about Data Storytelling than I. Though since it’s a topic I love and a topic I teach I will do my best to cover a few points for the curious in this post – especially the overlooked step of FINDING the data story.
What is Data?
You can Google the definition of data and find a slew of different answers, but one simplistic way to think about data is how my favorite Statistics textbook defines the term: “Data are usually numbers, but they are not ‘just numbers.’ Data are numbers with context.” (Yates, et al. The Practice of Statistics 3rd Edition.) So when we pull quantitative variables and qualitative (categorical) variables together, we are essentially giving meaning to what was otherwise a set of lonely numerical values.
What is Data Storytelling?
In my humble opinion, data storytelling takes the data (aka numbers in context) and, not only translates it into consumable information, but creates a connection between the audience and the insights to drive some action. That action might be a business decision or a “wow, I now appreciate this topic” response, depending on the context and audience.
A Short Guide to Data Storytelling
There are a few steps to telling a data story, and they could get complicated depending on your data type and analysis. And since your and your audience’s interests, background, and ability to draw conclusions plays into your storytelling, this process of finding and telling a data story could easily detour and fall into rabbit holes. Here I will map out a few general steps for both exploratory and explanatory analysis to help you simplify the complex both in process and in message.
1. Define Your Audience and Determine Their Objectives
This is important. And you’ll need to continue circling back to your audience throughout all of the steps below. If you know your audience’s goals, you can more easily cancel out the noise in your data and define the right questions and metrics along the way.
2. Find the Data Story: Exploratory Analysis
a) Make a Picture
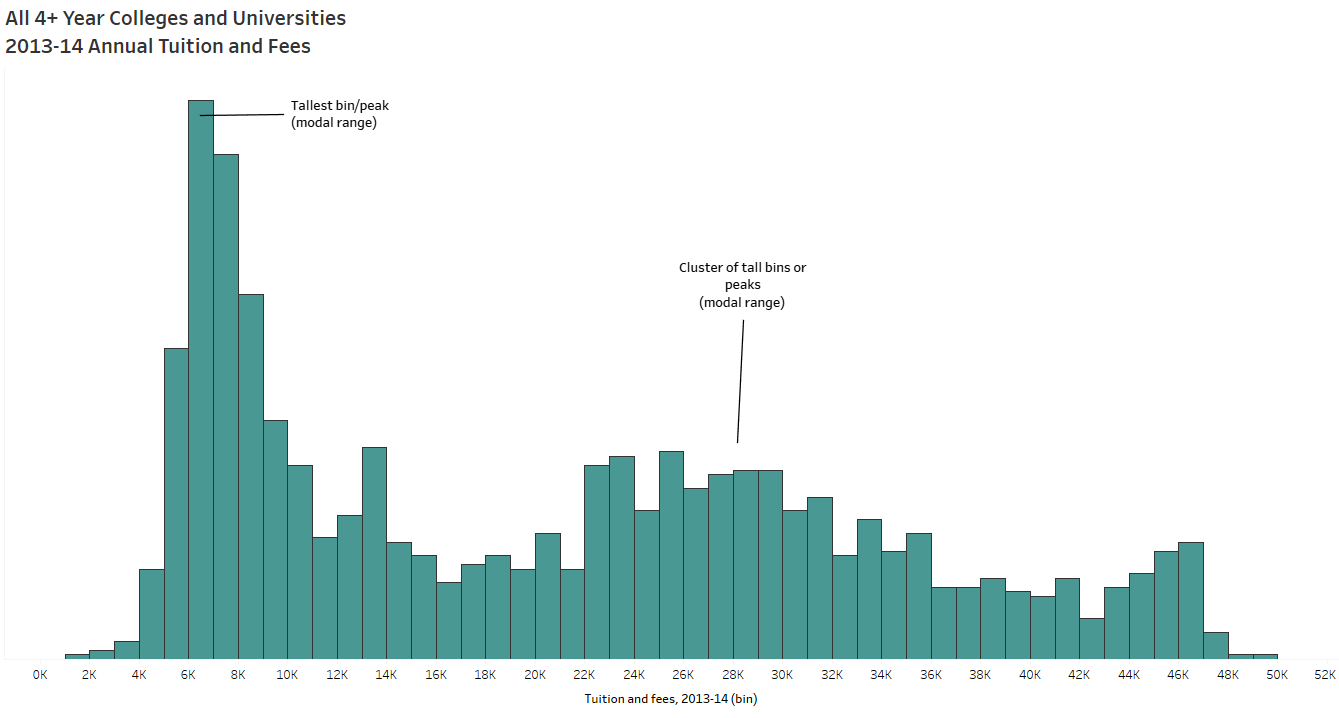
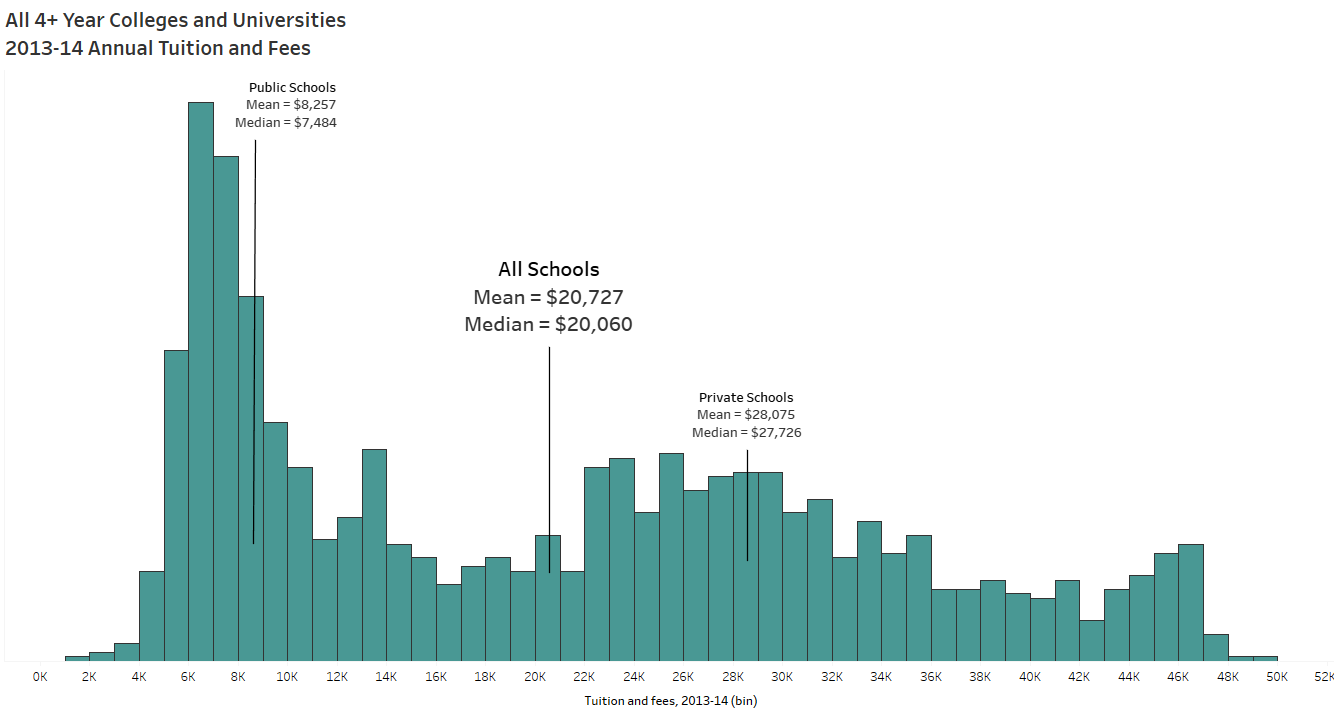
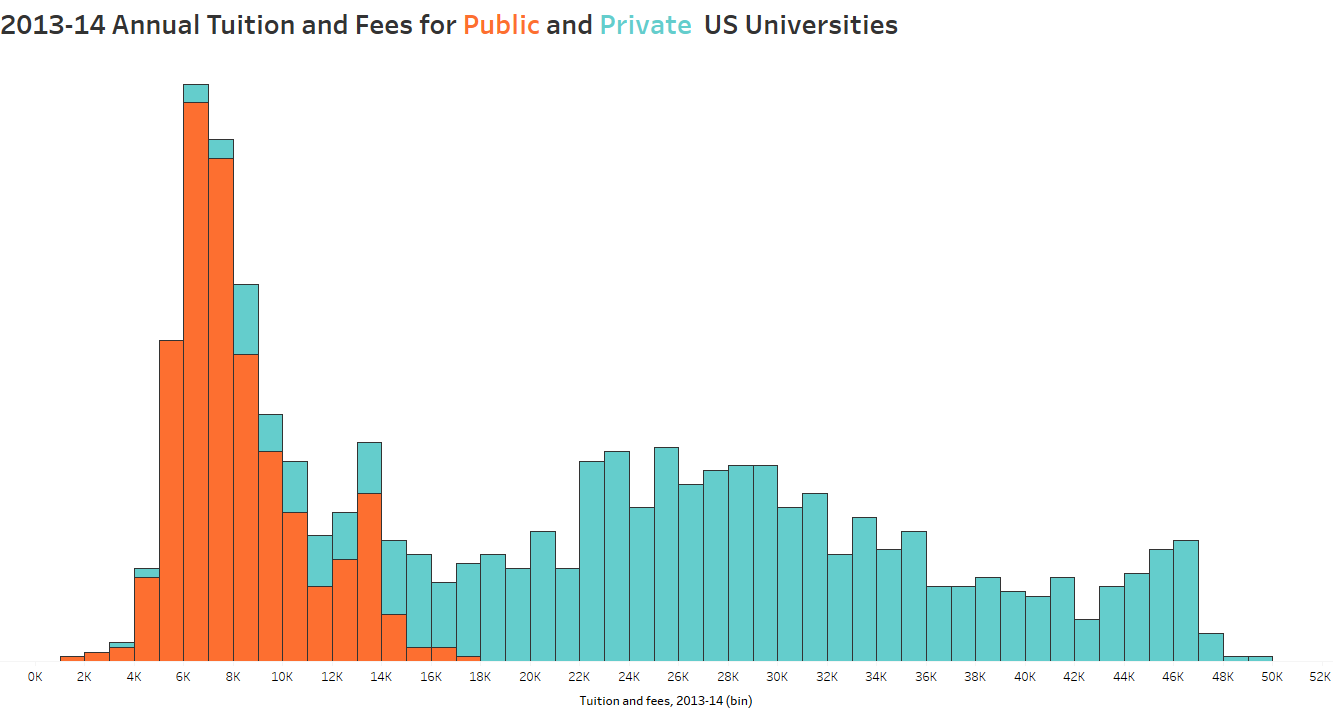
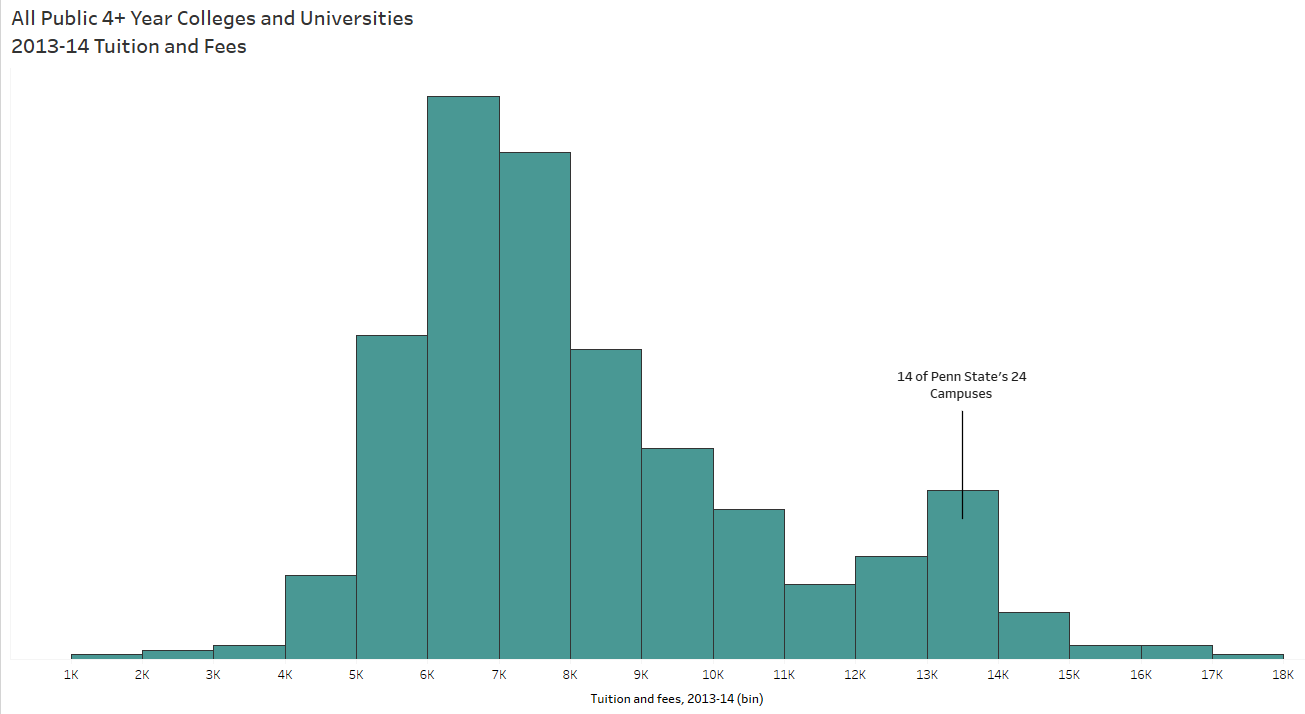
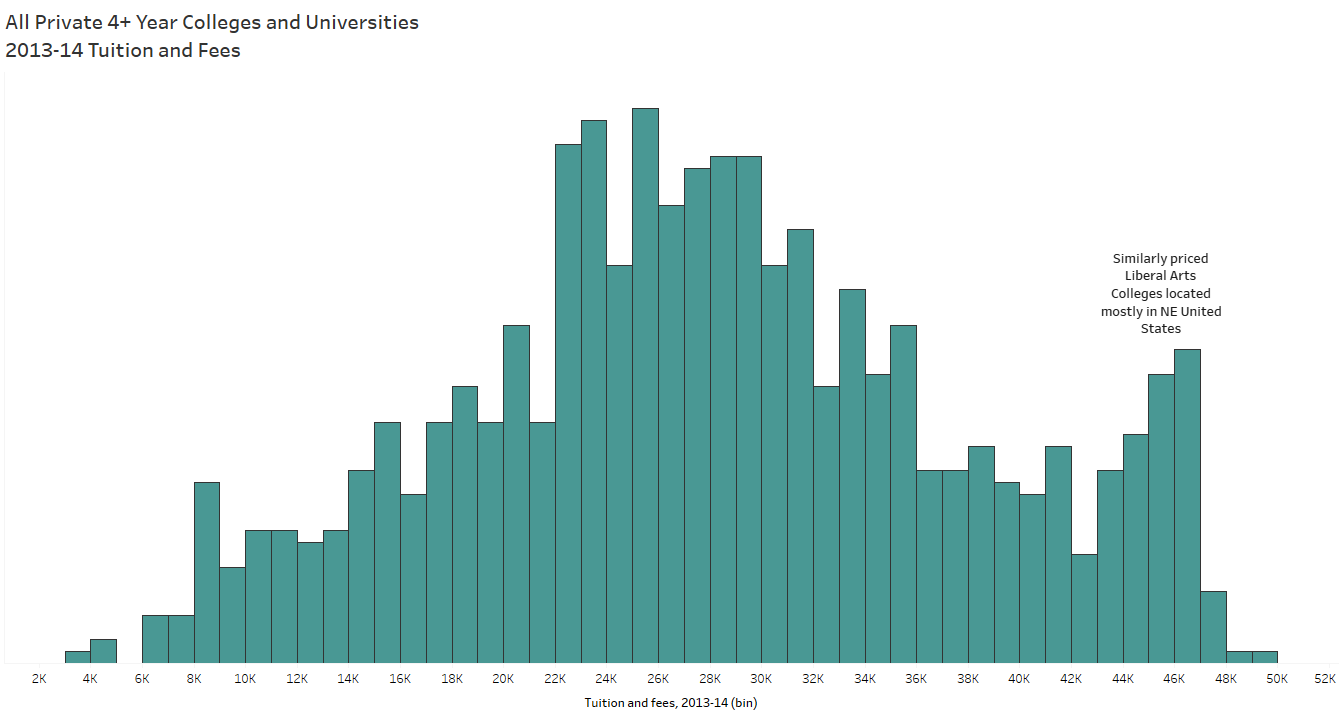
To tell a data story, you have to find the data story. And that begins with the exploratory analysis of your dataset – which should always begin with exploring your data visually. When I taught AP Stats I told the students the same thing I tell you now: When you get your hands on a set of data, MAKE A PICTURE. There are so many things a chart or graph (or multiple charts and graphs) can tell you about the data that tables and summary statistics cannot (including errors). See Anscombe’s Quartet for a demonstration of WHY.
Here I have a dataset from Wikipedia – Ironman World Championship Medalists. I must give credit to Eva Murray and Andy Kriebel for putting this data into .csv form for a 2019 Makeover Monday challenge .
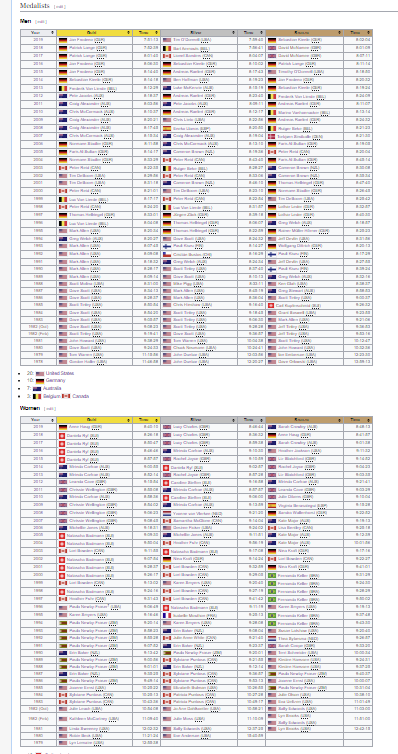
What story can we tell about this data from this format? It’s possible to draw some conclusions based on patterns we might be able to pull with our eyes; however, nothing exact and nothing conclusive. Instead, you might use data visualization tools to create charts and graphs — something like Tableau or Excel, or if you have time on your hands, a whiteboard and dry erase markers — to tease out a story.
b) Ask Questions. And Keep Asking Questions.
So where do you start? I always start with questions. Like, “Which countries have had the most medals in the Ironman Championship?”

We can also ask, “Which countries are the fastest, on average?” I’ve sorted low to high to reflect the fastest countries on top (faster = shorter duration):
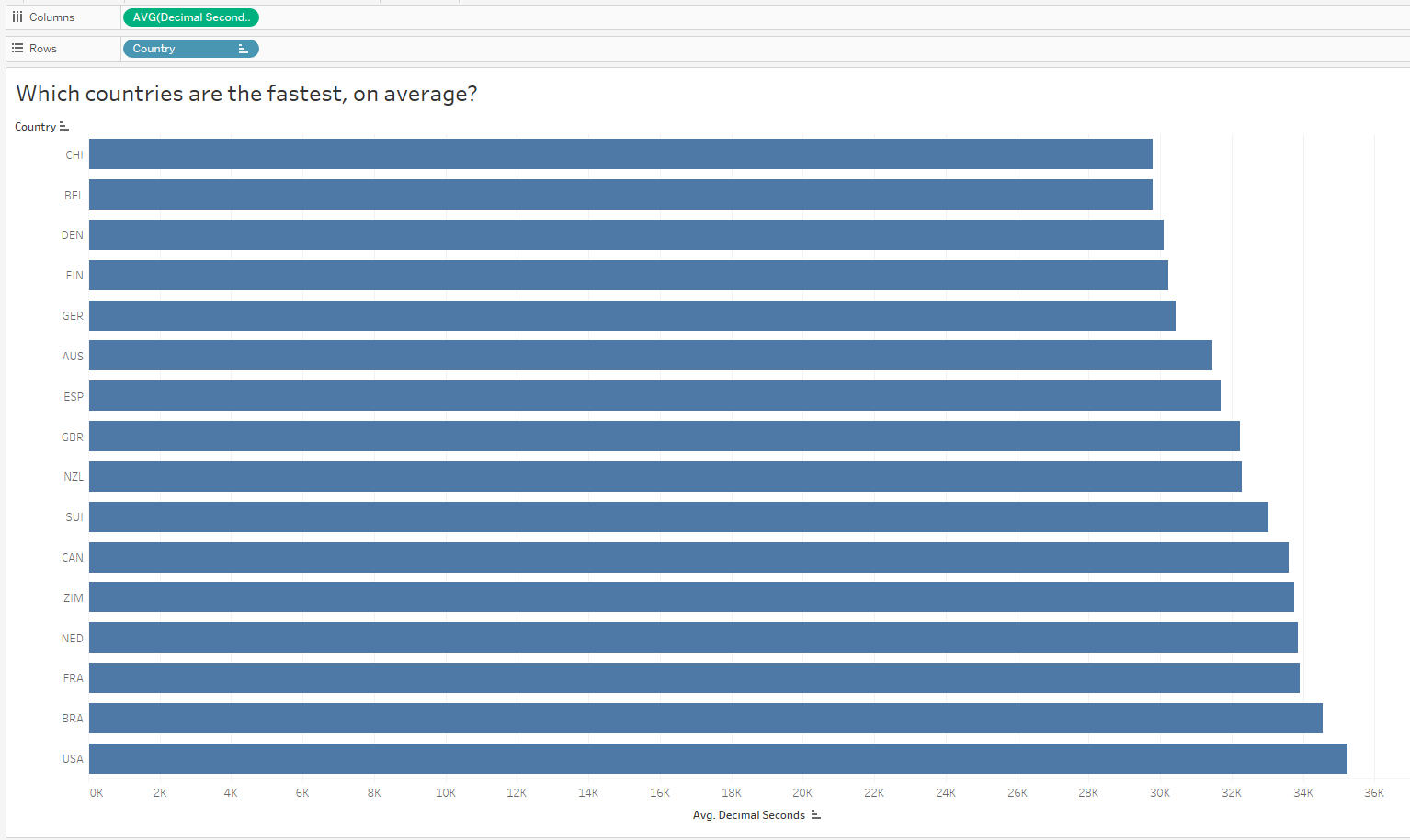
Oh that is interesting – I did not expect to see the US at the bottom of the list given they have the most medals in the dataset. But since I looked at all medals and did not only consider GOLD medals, I might now want to compare countries with the most gold medals. It’s possible the US won mostly bronze, right?
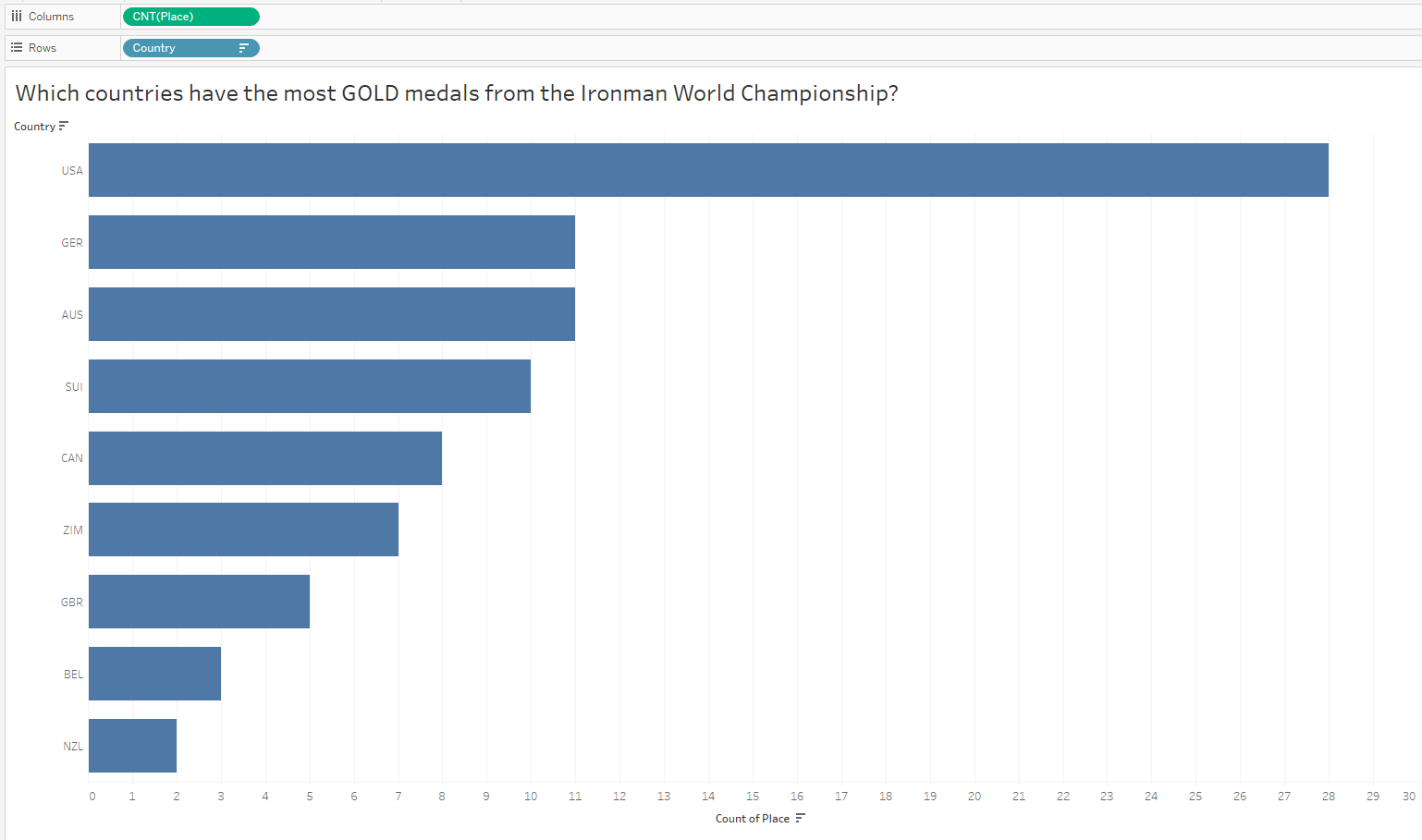
Interesting! I did NOT expect to see the US at the top of this chart after my last analysis. Hmmmm…
c) Don’t Assume, Ask “Why?”
And as you continue to ask questions, you’ll pull out more interesting insights. Since the distribution of gold medals looks similar to the distribution of all medals, I’m still quite curious why the average times for the US is higher than other countries when they have an overwhelmingly large number of gold medals (and gold medals = fastest times). There MUST be some other variable confounding this comparison. So now I’ll slice the data by other variables — now I’ll look at gender, and compare the overall average finish times of males vs females:
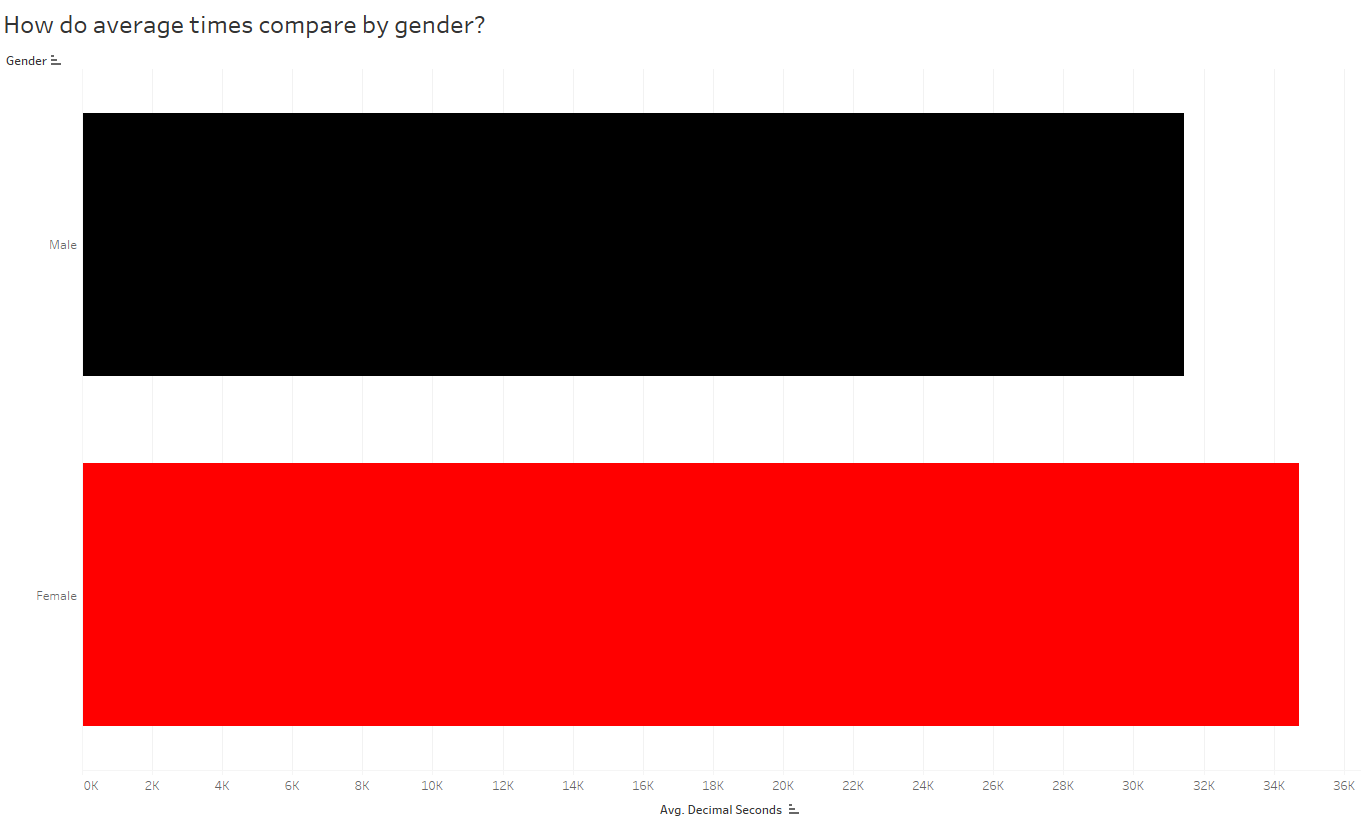
So if males are, on average, faster than females then maybe we should look at the breakdown of males vs females among countries. Is it possible the distribution of males and females differ by country?

Hmmm, it looks like the top countries, by average time, are represented by male athletes only. Meanwhile, females, whose times are slightly slower than males, make up a large proportion of the remaining countries.
Since the above chart is comparing average race times, let’s bring in some counts to compare the number (and ultimately proportion) of male vs female athletes in each country.
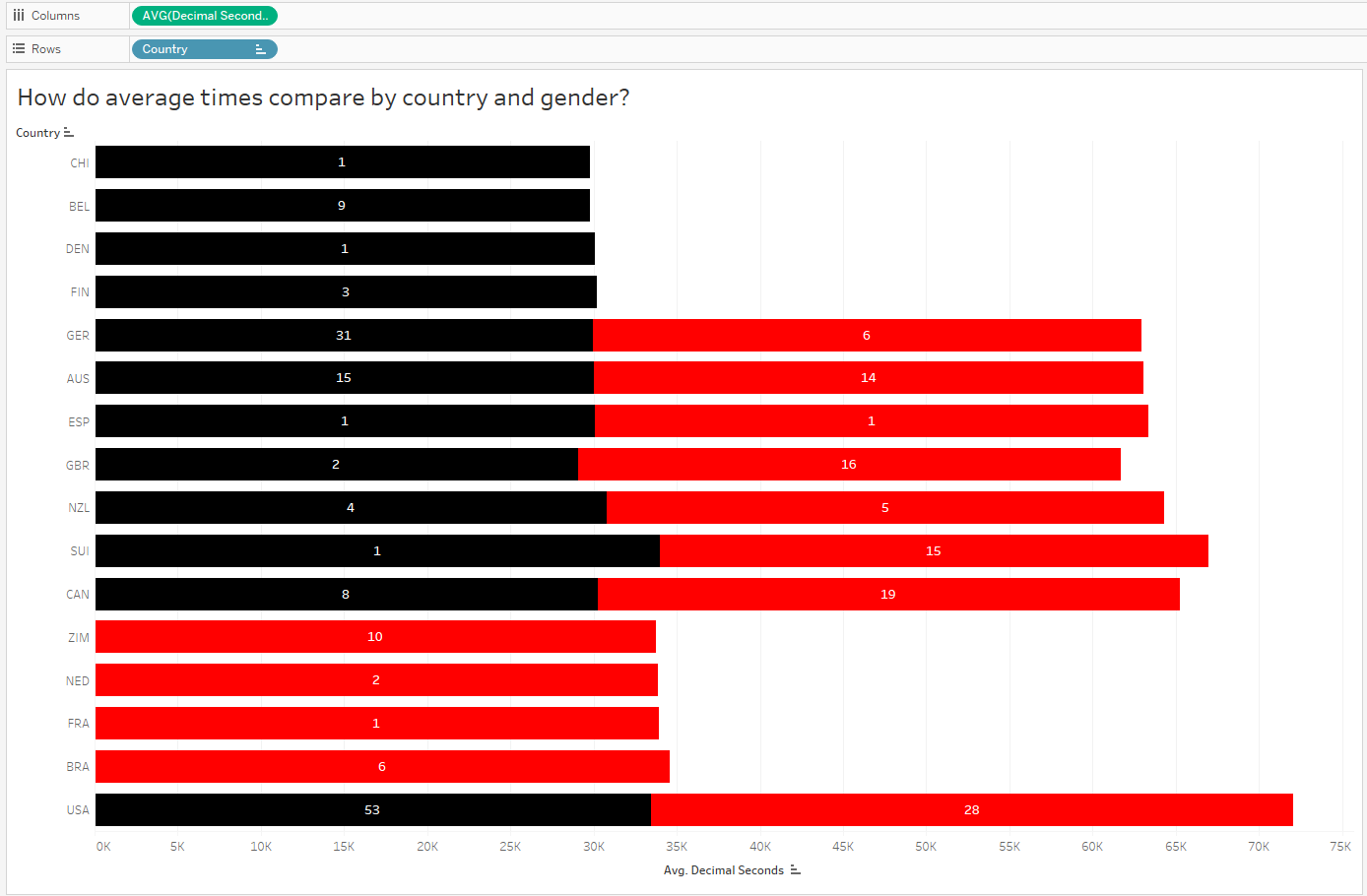
Alright, so now it makes sense that the overall average time for countries with a large proportion of female medalists will appear slightly longer than those with only males. Next I’d like to compare male and female finish times for ONLY gold medalists:
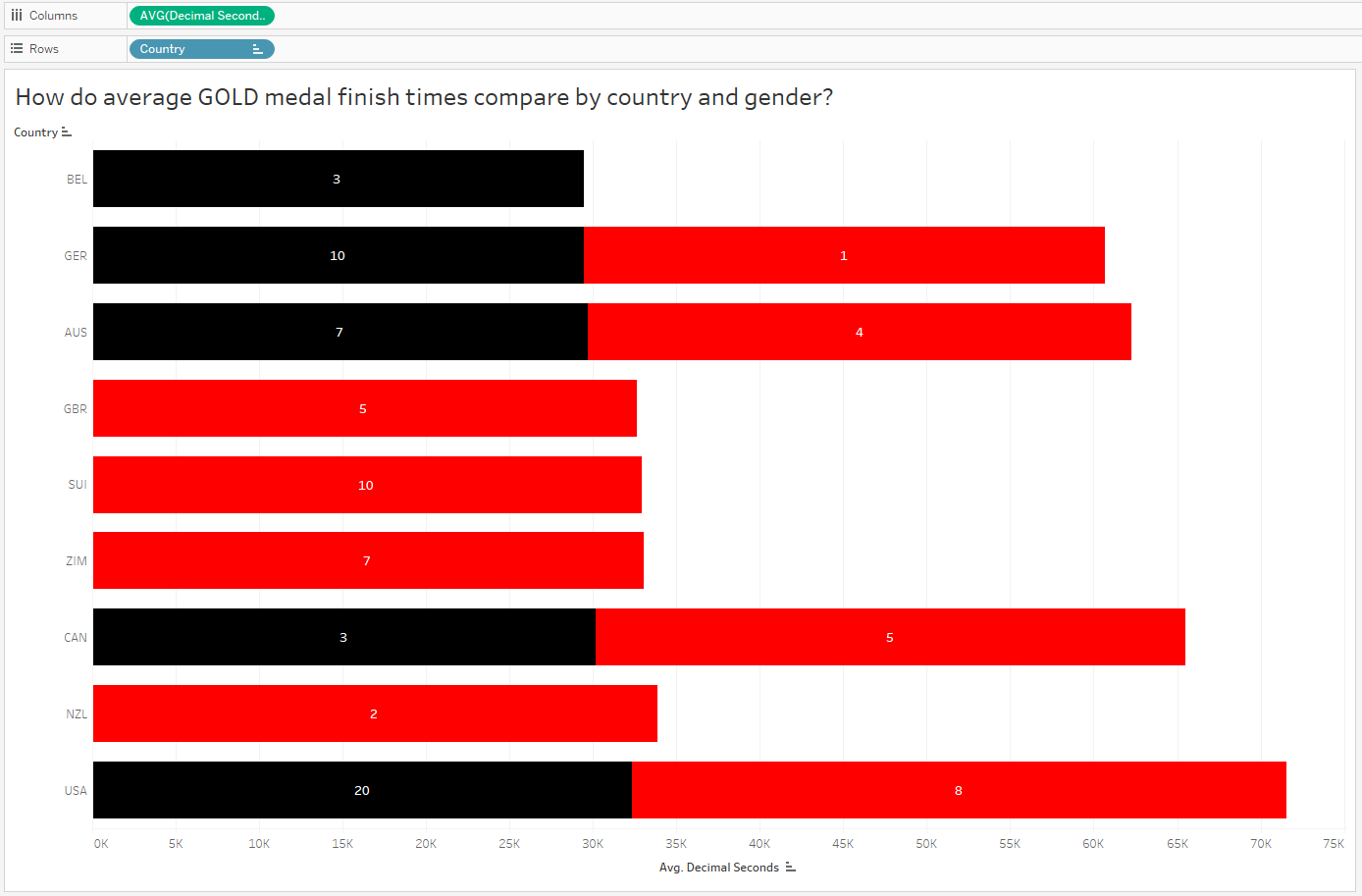
Wow, interesting! Of the 9 countries with gold medals, 8 of them have female representation on the 1st place podium. And 4 of those 9 countries ONLY have female representation at gold. But this doesn’t explain why the US has taken home so many more gold medals than other countries, while the overall average finish times for US finishers (and gold medalists too) are slower! What’s going on?
Is the YEAR a factor? When did the US win gold medals?
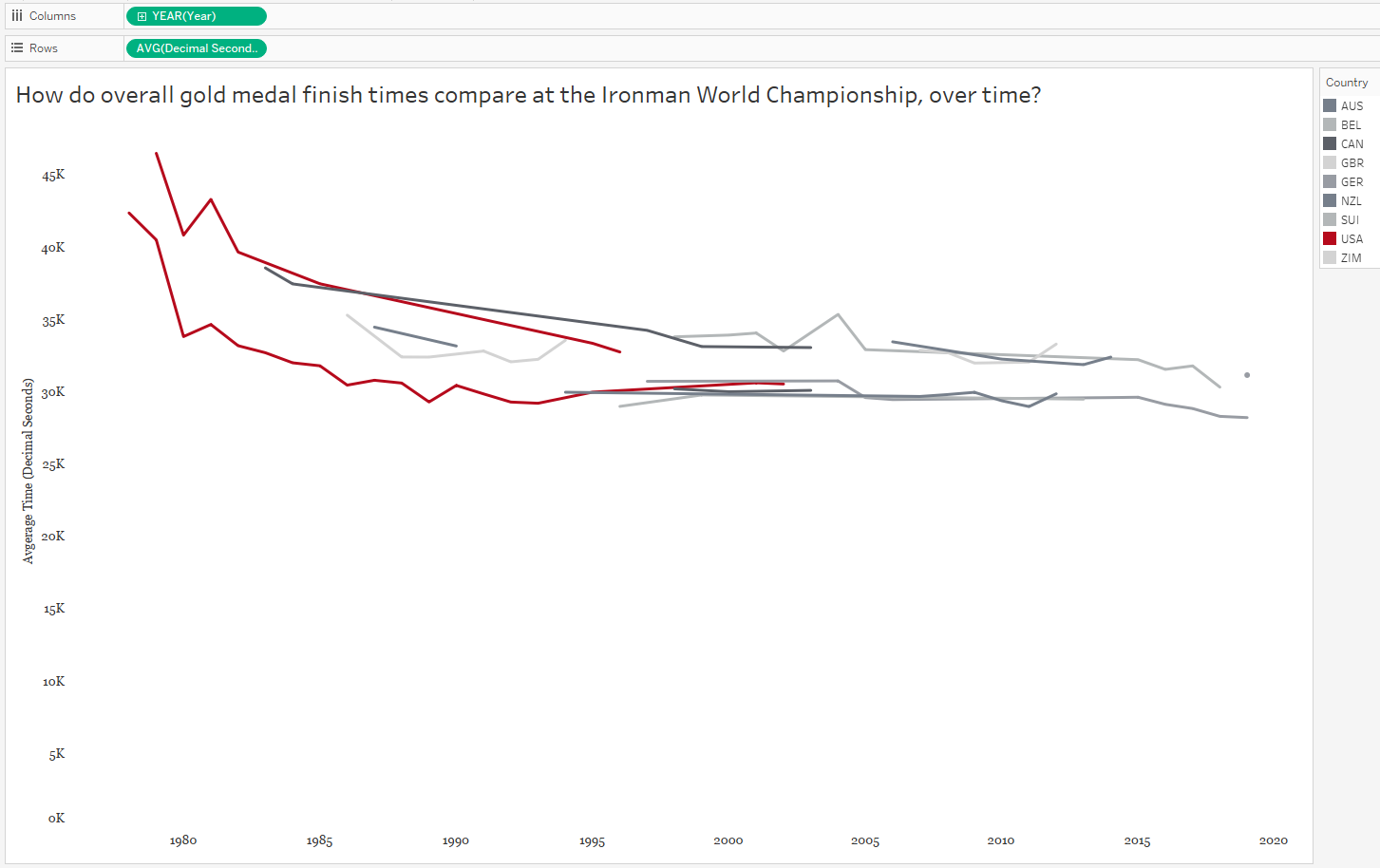
In the above graph, each country is now represented by a line graph (or two lines, if they both females and males won gold medals for that country). But I’ve changed the red color to highlight the US and shades of gray to put the other countries in the background. Looking at the above graph, we can see the overall finish times have decreased over time. AND we can see the US, for both males AND females, haven’t won gold medals in over a decade. So the two confounding variables we found for the race time paradox, as we could call it, were both gender AND year.
d) Focus on One Story
At this point I need to narrow down my context and define what questions I want to ask and which metrics will answer those questions. It’s hard to listen to someone’s story when it has a million tangents, right? So don’t tell those meandering stories with data, either. Pick a topic – and don’t forget to consider your audience. I’ve decided to step away from the specific countries, and compare only those GOLD MEDAL race times by gender over time. I’m curious to learn more about WHY those finish times fell over time!
e) Find the Right Analysis for Your Story
Once you determine which variables are involved in your analysis, you can choose the appropriate chart to dig deeper into the insights. Because I chose to focus on gold medal finish times over the years, a time series analysis is appropriate. Here is a great reference tool for matching your analysis to your questions:
Let’s bring in years and create a timeline:

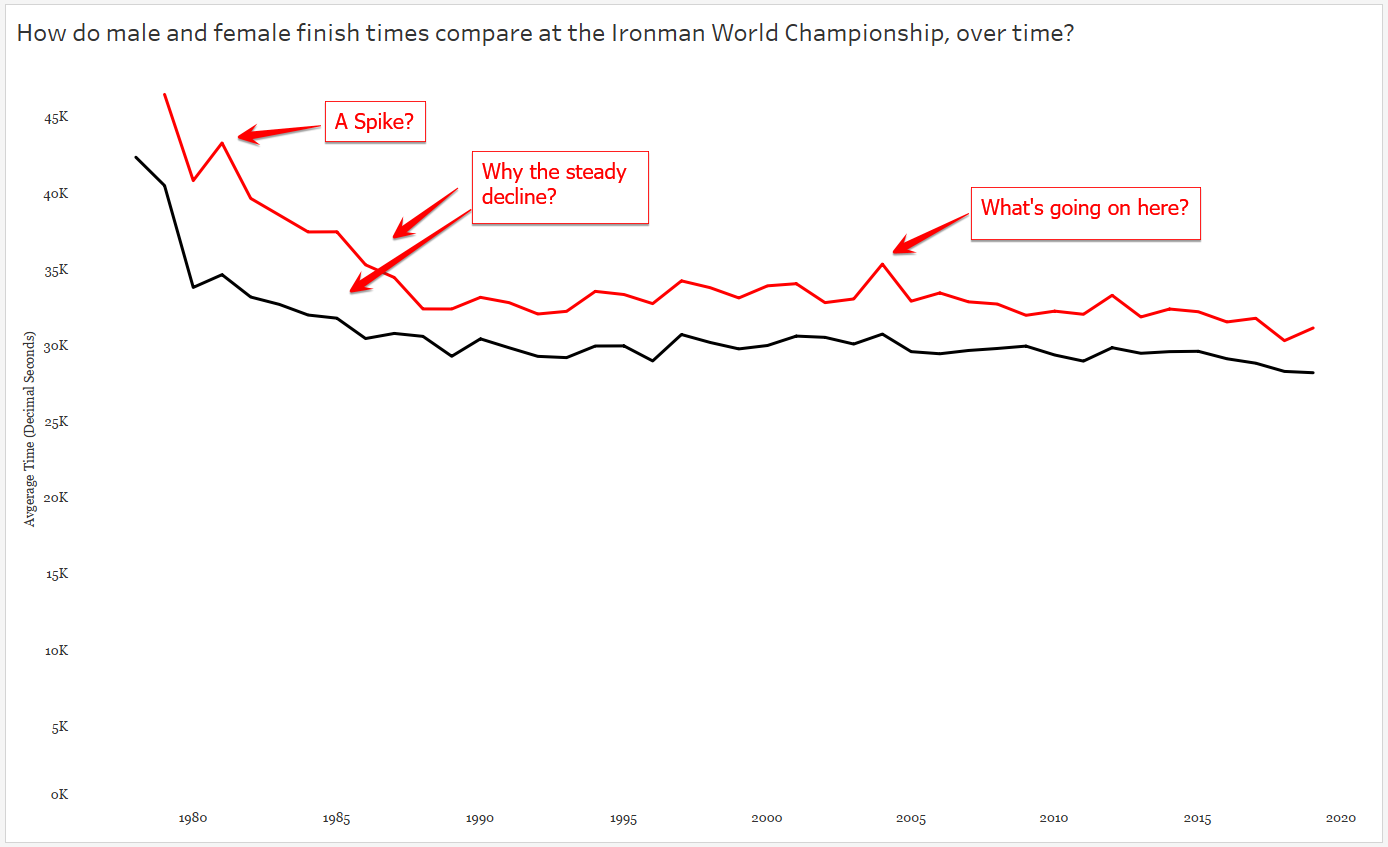
And clearly there is more to investigate here – like why, if I stick with Tableau’s default aggregation of SUM do I see a spike here? After some Googling – ah, that year TWO separate Ironman Championships were held. So even though I’m looking only at times for the male and female gold medal times, there’s one year that’s doubled because there are two gold medal times per gender. Easy fix, let’s change the aggregation to AVERAGE, which will only affect this one year. Now let’s tease out our big story by looking at our chart and asking more questions :
3. Explanatory Analysis
Once you’ve explored the data and you’ve asked and (tried to) answer questions arising from the analysis, you’re ready to pull the story together for your audience.
a) Design with the Audience in Mind
Without calling attention to it, I began this step above. As you can see, I changed up the colors in my charts when I brought in the variable of gender. I did this for you, my audience, so you could easily pick out the differences in the race times for males and females. This is called “leveraging pre-attentive attributes“, which basically means here I’ve used color to help you see the differences without consciously thinking about it. In my final version I will need to make sure the difference in gender is clear and easy to compare (more on this later).
Color also needs to be chosen with the audience in mind. Not only do the colors need to make sense (here I chose the Iron Man brand colors to distinguish gender), they also need to be accessible for all viewers. For example the colors chosen need to have enough contrast for people with color vision deficiency. (For more in-depth information about the use of color, Lisa Charlotte Rost has an excellent resource in her blog Data Wrapper.) Too much of a good thing is never a good thing, so I chose to keep all other colors in the chart neutral so other elements of the story do not compete for the audience’s attention.
Also, without telling you, I’ve stripped away some of the unnecessary “clutter” in my chart by dumping grid lines and axis lines. When in doubt, leave white space in your charts to maximize the “data-to-ink ratio” – save your ink for the data and skip the background noise when possible.
Finally, I’m sticking with my old standard font (Georgia) for the axes and (eventually in the final version, the title). A serif typeface, Georgia is easy to read on small screens or screens with low resolution.
b) Call Attention to the Story/Insights/Action
Here I’ve answered a couple of questions that arose from the data, and you, my audience, never had to switch tabs to go looking for answers. (Re-reading my words I feel like I must sound like Grover in The Monster at the End of the Book.)
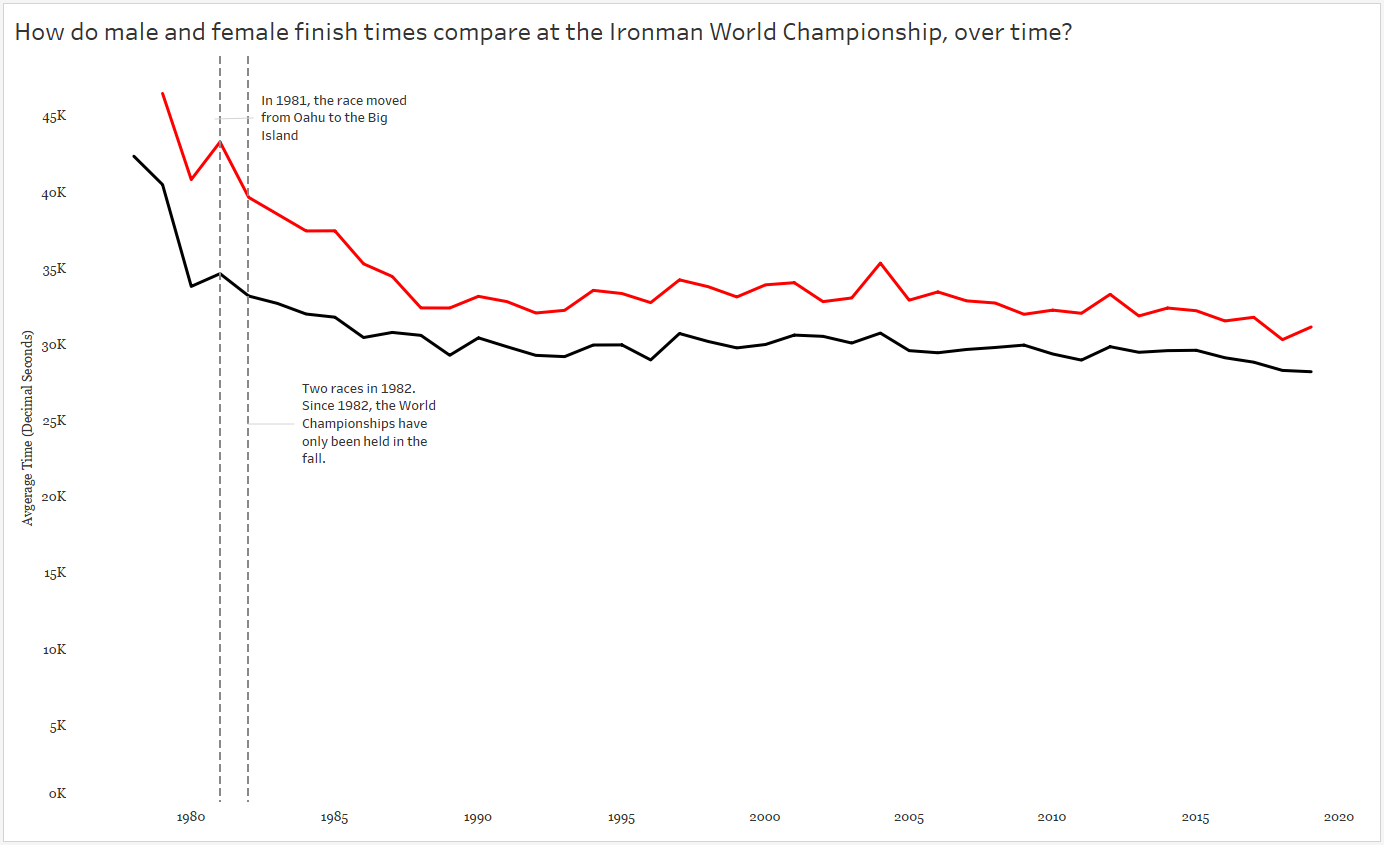
That increase in race time in 1981? A course change! Only a slight increase in time for males, but a big slow down for the females.
Also note I included an annotation for the two races in 1982.
It’s interesting to see the steady decline in finish times throughout the 1980s — what might have caused this decline? And remember, a decline in finish times means GOLD MEDALISTS GOT FASTER.
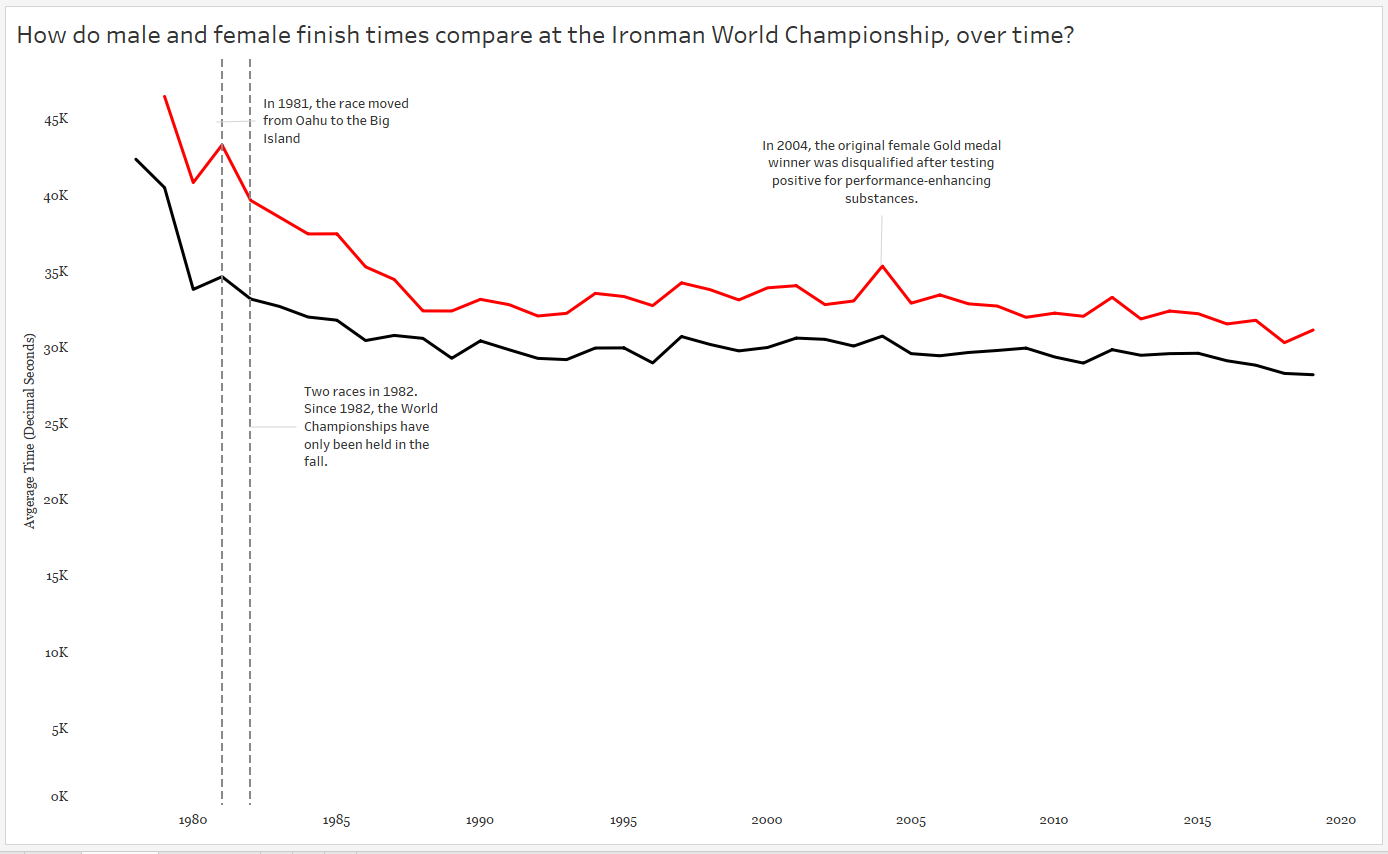
And finally, I called attention to the spike in 2004. Apparently the gold medal finisher was DQ’ed for doping…which makes me wonder about the sharp decline in the 1980’s.
c) Leverage the Title
In the words of Kurt Vonnegut, Pity the Readers. Be as clear and concise and don’t assume they understand your big words and complicated jargon. Keep it simple! One thing I left out of my original title was the very specific use of ONLY gold medal data here. Without that information, the reader might think we were averaging all of the medalist’s times each year!
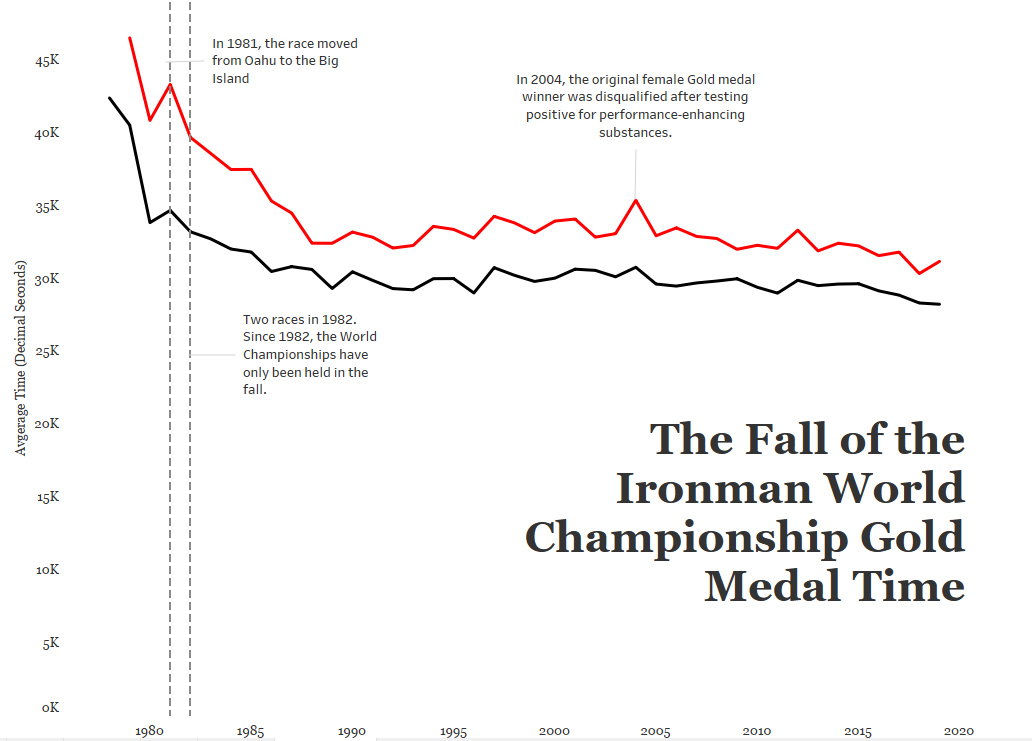
But is it clear what the red and black colors mean? And are there any additional insights I can throw into my title without being verbose?
Color legends take up dashboard space and I’m a bit keen on the white space I’ve managed to leave in my view. In my final version, I’ve colored the words MALE and FEMALE in the subtitle to match the colors used in the chart, serving as a simple color legend.

A subtitle can help guide the audience to a specific insight, in this case the overall decline in gold medal times by both males and females since the first Ironman World Championship in 1978.
Other Considerations
My final version is interactive, as you can see here. I’ve added notes to the tooltip to display the percent change in winning times by gender each year when the audience interacts with the chart:
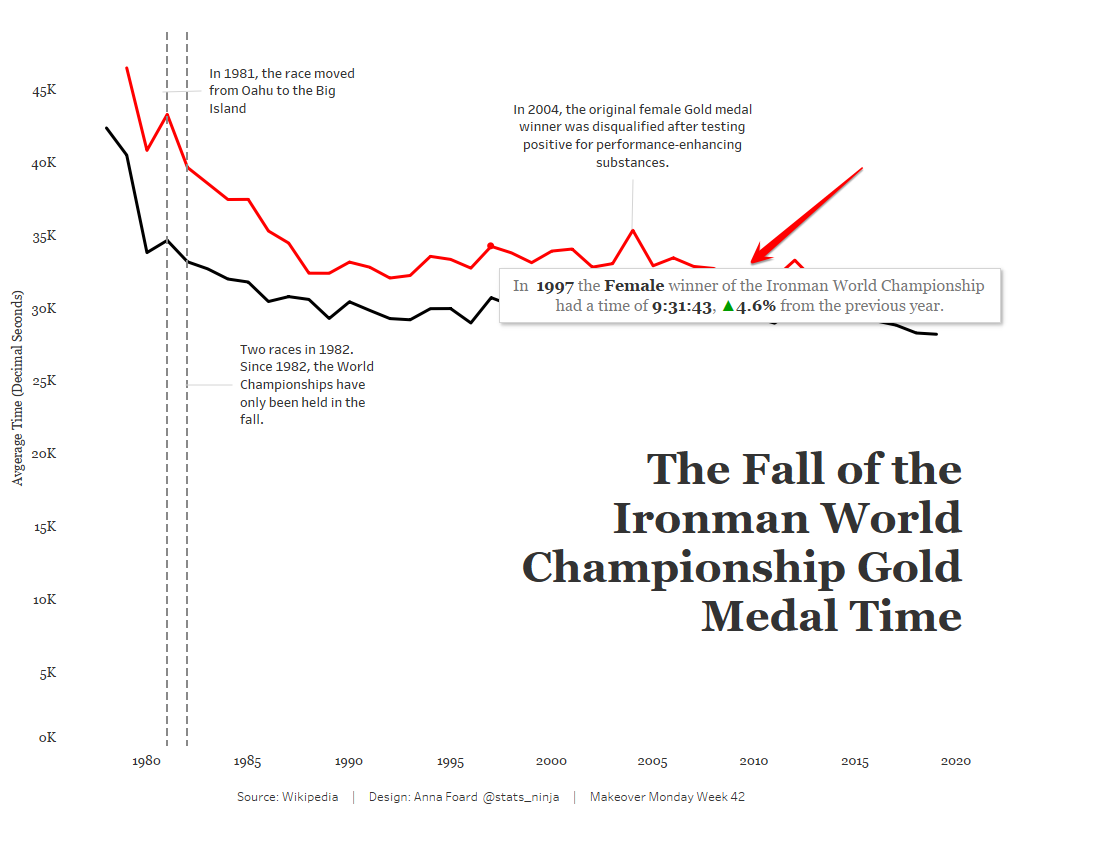
If you’re using multiple charts for your data story, you’ll also want to consider layout and how the audience will likely consume that information. Tableau has an excellent article on eye-tracking studies to help data story designers create a flow with minimal cognitive load and maximum impact.
Other Data Storytelling Resources
Storytelling with Data – Cole Nussbaumer Knaflic
Info we Trust – RJ Andrews